Apache Druid is an amazing database for powering a modern analytics application. Typically an analytics application requires sub second response times under heavy load and TB/PB scale. This means that doing as much processing as possible (other than aggregations which Druid does really well) in the ingestion or in the pipeline before Druid is often helpful.
One use case where processing needs to be done in the pipeline before Druid is when you have multiple streams of data flowing into Druid and the streams need to be joined for analytics. With the most recent release of Druid joining data while ingesting from batch sources is well supported using the multi-stage query engine (MSQ), however joining streaming sources is not possible during ingestion and hence the join has to be done at query time. This impacts query performance and hence the need to do the join in the pipeline upstream of Druid.
A typical example of this use case is analysing order information. Typically orders are in one stream and order details (order line items) are in another stream. To analyse orders the data needs to be joined on the order_id. One approach is to ingest order and orderdetail into separate data sources and join in the query. However typically both order and detail information runs into millions of records. Hence the preferred approach is to build a pipeline with Flink, Kafka and Druid.
Data and setup
The data setup consists of two files
- orders.csv – This is a csv file with order information. The columns are orderid,orderdate,deliverydate,shipppeddate,status,comment and orderno.
- orderdetails.csv– This is a csv with orderid,itemname,qty,rate and lineno.
For this demo I have created two kafka topics – orders and orderdetails which contain the contents of these two files and third one called joineddata which receives the joined stream from Flink. My aim is to put together the following pipeline.
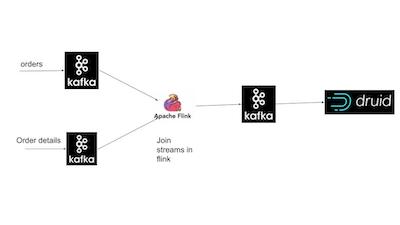
To setup this pipeline
The installation needs to be in the above order as Druid includes zookeeper while Kafka does not. Use the quick start guides which each of the above products to start the services.
Setting up the Flink Pipeline
Download the the data files orders.csv and orderdetails.csv. Create three topics in kafka – orders,details and joineddata
./kafka-topics.sh --create --topic joineddata --bootstrap-server localhost:9092
upload orderdetails.csv to the kafka topic
cat orderdetails.csv|./kafka-console-producer.sh --bootstrap-server localhost:9092 --topic orderdetails
Download the Flink code and pom.xml are here
The code does the following
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
KafkaSource<String> source1 = KafkaSource.<String>builder()
.setBootstrapServers("localhost:9092")
.setTopics("orders")
.setGroupId("my-group")
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
KafkaSource<String> source2 = KafkaSource.<String>builder()
.setBootstrapServers("localhost:9092")
.setTopics("orderdetails")
.setGroupId("my-group1")
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
The above code creates a stream environment (env) and stream table environment (tableEnv). Setup two Kafka sources in Flink and ingest from orders and orderdetails.
DataStream<String> text1 = env.fromSource(source1, WatermarkStrategy.noWatermarks(), "Kafka Source1");
DataStream<String> text2 = env.fromSource(source2, WatermarkStrategy.noWatermarks(), "Kafka Source2");
The above converts the Kafka streams into text streams
DataStream<Tuple7<Integer,String,String,String,String,String,String>> orders=text1.map(new MapFunction<String, Tuple7<Integer,String,String,String,String,String,String>>()
{
public Tuple7<Integer,String,String,String,String,String,String> map(String value)
{
String[] words = value.split(","); // words = [ {1} {John}]
return new Tuple7<Integer,String,String,String,String,String,String>(Integer.parseInt(words[0]), words[1],words[2], words[3],words[4], words[5],words[6]);
}
});
DataStream<Tuple5<Integer,String,String,String,String>> details=text2.map(new MapFunction<String, Tuple5<Integer,String,String,String,String>>()
{
public Tuple5<Integer,String,String,String,String> map(String value)
{
String[] words = value.split(",");
return new Tuple5<Integer,String,String,String,String>(Integer.parseInt(words[0]), words[1],words[2], words[3],words[4]);
}
});
In the above code, tuples are extracted from the text streams. Orders has 7 fields and orderdetails has 5 fields.
Table inputTable = tableEnv.fromDataStream(orders);
tableEnv.createTemporaryView("orders", inputTable);
Table inputTable1 = tableEnv.fromDataStream(details);
tableEnv.createTemporaryView("details", inputTable1);
Table resultTable = tableEnv.sqlQuery("SELECT orders.f0,orders.f1,orders.f2,orders.f3,orders.f4,orders.f5,orders.f6,details.f1,details.f2,details.f3,details.f4 FROM orders inner join details on orders.f0=details.f0");Convert the tuples to tables and do the join in sql. The join is on orderid which is the first field (f0) in both tuples.
TupleTypeInfo<Tuple11<Integer,String,String,String,String,String,String,String,String,String,String>> tupleType = new TupleTypeInfo<>(Types.INT(), Types.STRING(),Types.STRING(),Types.STRING(),Types.STRING(),Types.STRING(),Types.STRING(),Types.STRING(),Types.STRING(),Types.STRING(),Types.STRING());
DataStream<Tuple11<Integer,String,String,String,String,String,String,String,String,String,String>> dsTuple = tableEnv.toAppendStream(resultTable, tupleType);
DataStream<String> joined=dsTuple.map(new MapFunction<Tuple11<Integer,String,String,String,String,String,String,String,String,String,String>,String>()
{
public String map(Tuple11<Integer,String,String,String,String,String,String,String,String,String,String> value)
{
String words = value.f0.toString()+","+value.f1+","+value.f2+","+value.f3+","+value.f4+","+value.f5+","+value.f6+","+value.f7+","+value.f8+","+value.f9+","+value.f10;
return words;
}
});
The above code converts the joined results into tuples and then concatenates the tuples
KafkaSink<String> sink = KafkaSink.<String>builder()
.setBootstrapServers("localhost:9092")
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopic("joineddata")
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
.setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.build();
joined.sinkTo(sink);
env.execute("Kafka Example");
Publish the join results to the Kafka topic joineddata and execute the streaming environment. Build the above code as a maven build and run it in Flink
./flink run <jar file>
Use the Druid ingestion spec (github) to start a Druid Kafka ingestion task. This should get the joined data into Druid and you should see the source in Druid
Conclusion
There are many use cases which require joining data coming through multiple Kafka streams into Druid. One way of handling such use cases is to join the data outside Druid. In this blog an approach using Flink to join the data was demonstrated. This is a scaleable approach that can be used with streams with large throughput and allows Druid to be used for the adhoc aggregations.
